
Cleaner. Smarter.
A service for high-throughput image dataset optimization through 2D image analysis and structural cleanup
Next Frontier In Extending Computer Vision Performance
Interested in how you can save while scaling up AND lower the noise floor to extend Computer Vision performance?
For the past five-plus years, scaling up computation power and time, data size, and modeling produced dramatic gains in Deep Learning. Many developments are now saturating, producing diminishing returns. At today’s scale even modest efficiency improvements translate into meaningful savings in training time, inference cost, and infrastructure spending.
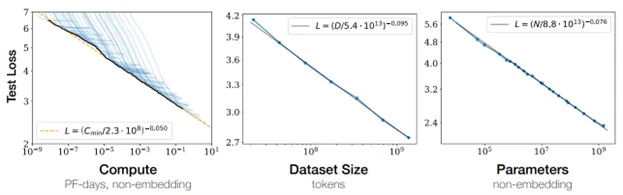
J. Kaplan, S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, S. Gray, A. Radford, J. Wu, and D. Amodei, “Scaling laws for neural language models,” arXiv preprint arXiv:2001.08361, Jan. 2020. doi: 10.48550/arXiv.2001.08361.
Efficiency does not come from brute-force scaling. And developers are beginning to notice.
“If you just put in more compute, you put in more data, you make the model bigger — there are diminishing returns. In order to keep the scaling laws going … we also need new ideas.”
- Robert Nishihara, Anyscale co-founder
For years, most of the attention - and nearly all the budget - went into models, computation, and raw data volume. Recently, data cleanliness and preparation has emerged as the next frontier for improving performance.
"I think the most important shift the AI world needs to go through this decade will be a shift to data centric AI."
- Andrew Ng, Founder of DeepLearning.AI; Managing General Partner of AI Fund; Exec Chairman of LandingAI
The reason is not philosophical, it is structural.
Scaling Laws Have Regimes
Empirically, scaling laws operate across regimes tied to signal and noise:
1. Signal-limited: initially, performance improves rapidly with scale, but eventually saturates
2. Noise-limited: improvements slow dramatically with saturation, approaching a “noise floor”
3. Noise floor: additional scaling yields no meaningful improvement
If your computer vision models feel “stuck,” the explanation is rarely architectural. It’s not because you need more parameters. And it’s definitely not because you need more GPUs.
It’s that you’re operating near the noise floor.
And when you’re near the noise floor, adding more parameters, data, or computation is inefficient. Scaling costs rise exponentially while performance improvement slows. You can add more data, more computing power, more training cycles - all you get is marginal improvement wrapped in much greater cost. That’s the cue to stop scaling the model, and start fixing the data.
Data Cleaning Changes the Equation
Improving dataset quality does two things simultaneously:
1. It reduces noise in the training data, improving optimization efficiency. The model compresses reducible entropy faster, requiring fewer updates, less computing, and less time to reach the same performance.
2. It lowers the noise floor itself, extending the useful range of scaling. By reducing irreducible entropy in the dataset, you unlock additional performance without changing the compute+data+model budget. Yes! Reducing irreducible entropy by removing the cause – data uncertainty.
Scaling costs are huge and marginal inefficiencies can compound. So this matters in large systems.
At this point there’s a reasonable question to ask:
“Data Wash, this sounds good in theory, but how does it help me in practice?”
Here’s the answer that actually matters:
You don’t lower the noise floor by changing the model. You lower it by changing the data.
Bad data caps performance. No amount of scaling can out-learn mislabeled images, inconsistent annotations, distribution drift, or silent corruption hiding in your training set.
Data Wash focuses on the unglamorous work that scaling laws try to brute force away: removing contradictions, tightening labels and eliminating junk. We enable you to feed your model cleaner data. Cleaner data equals more efficient learning. It’s that simple!
Labels Are the Highest-Leverage Fix
Cleaner data comes from many places – dataset structure, curation, filtering - but label quality dominates for image datasets. Eliminate mislabels and you ensure highly accurate label structure.
The worst offenders are contradictory labels: the same visual pattern mapped to different labels. A cat labeled “dog” doesn’t just introduce noise - it raises the noise floor and raises the entropy of the target distribution itself. It increases irreducible error. From information theory, this is the most damaging source of error.
And it gets worse in the plot’s long tail. With Zipf distributions, rating data significance to data occurrence, rare images already suffer from sparse signal. A single mislabeled example can dominate an entire region of the tail, poisoning generalization exactly where models struggle most.
This is why mislabeled data is not just “bad data.” It actively limits scaling.
What Data Wash Does
We built Data Wash to attack this problem directly. Our roadmap prioritizes:
· Image label verification for structured datasets
· Image feature identification and labeling for unstructured data
Both capabilities are included in our planned 2026 beta release.
If you’re part of a computer vision team encountering diminishing returns - and you want to reduce cost and extend performance - we’re looking for beta partners who would benefit from improving image data quality at scale.
Better models don’t fix noisy data. Cleaner data extends scaling.
Interested in participating? Contact us.
2D Pixel Coordinated Analysis
The ONLY data quality tools for image datasets with actionable cleanliness insights based on the 2D information content of each image
Data Quality Tools For Images
The FIRST data quality platform to automate cleaning and optimizing of image datasets for preparation of computer vision model training
Data Scientists & Machine Learning Engineers SAVE:
Time
Money
Projects
Private Beta Launch in 2026
We’re preparing to launch Data Wash, a platform for high-throughput image dataset optimization through 2D image analysis and structural cleanup.
Before public release, we’re selecting a very limited number of early customer partners to onboard with reduced pricing during our beta phase.
If your team works with image datasets ≥100k samples, it could be a strong fit. If you'd like to be considered, connect with us now before our applicant list is closed.
The provided information does not constitute an offer or invitation to make offers or invitation to buy, sell or otherwise use any services, products and/or resources referred to on this website, and may be changed at any time. Contact us for more information.

Data Wash is transforming how image data is prepared and processed for deep learning models. We make massive image datasets move fast. And help data engineers & scientists be the project hero.
Don't be left in the noise! Turn your bottleneck into a competitive advantage.
ABOUT DATA WASH
We're on a mission to elevate data scientists & engineers, to help them spend more time innovating & creating and less time cleaning.
We make image dataset preparation and cleaning fast, predictable and scalable, so teams can accelerate their machine learning breakthroughs.
Join us for a data centric approach to building smarter AI models.
Built by scientists, for scientists.
Contact Us
© Data Wash. All Rights Reserved.